开云kaiyun(中国)官网 VAST+清华建议3D生成新范式, 空间智能密度操纵把算力花在刀刃上


若是把当今最热点的几条 3D 生成本领线放在一说念看,你会发现它们正在遭遇一个很像的问题。
作念 3D AIGC 的东说念主会发现,模子还是越来越会 “生成一个东西”,但生成收尾的复杂度很固定,不够天真;作念图形学和渲染的东说念主会更介意,3D 默示到底能不成把有限的筹画预算用在最要害的所在;作念游戏、XR 和交互内容的东说念主则会持续追问,合并个 3D 钞票能不成既有高质料版块,也有轻量版块,而不是每次齐从头作念一套。
这些问题背后,其实齐指向合并个中枢矛盾:
今天好多 3D 生成本领,天然能生成 3D 收尾,但还不够 “会分拨资源”。
以 3D 高斯默示为例,那里高斯球应该密少许,那里不错零散少许;那里值得放更多默示智商,那里只需要一个稚童近似,好多本领其实并莫得信得过学会。现存本领更像是在用一种固定模板生成 3D,而不是凭据物体本人的结构复杂度,自顺应地决定 “该放若干高斯、放在那里”。
SIGGRAPH 2026 论文《Generative 3D Gaussians with Learned Density Control》,想贬责的恰是这个问题。

论文:《Generative 3D Gaussians with Learned Density Control》
论文承接:https://arxiv.org/abs/2605.16355
这篇责任来自 VAST 和清华大学,建议了一种新的 3D 默示神气 Density-Sampled Gaussians(DeG)。它的决策不是简便生成固定数目的 3D 高斯球,而是让模子我方学会一种 “高斯球采样战略”: 在复杂区域多放高斯球,在简便区域少放高斯球,而且这种战略还能胜利从渲染短处里学出来。
这件事听起来像是工程优化,但其实相等要害。因为它决定了 3D 生成收尾最终是一个 “看起来还行但很纷乱的静态输出”,如故一个信得过不错按预算伸缩、按需求部署、按场景适配的 3D 默示。
夙昔一段时候,3D 高斯之是以火,一个很遑急的原因是它在画质和着力之间找到了很好的均衡。它不必像传统网格那样依赖复杂拓扑,也能渲染出高质料收尾。3D 高斯的优化过程有一个要害优点,也恰恰亦然它最难被 Diffusion 等生成式模子摄取的部分,等于空间密度操纵 (density control)。
在 3D 高斯优化过程里,优化算法会束缚作念 密集化 (densification) 和 零散化 (pruning)。简便勾通等于:
若是某个局部没拟合好,就往那里 “补” 更多高斯;若是某些高斯孝顺不大,就把它们删掉。
这套机制很灵验,因为现实里的 3D 物体本来就不是均匀复杂的。边缘、薄结构、纹理剧烈变化的区域,需要更多默示智商;而大块平整、变化不大的区域,其实没必要堆太多高斯球。
问题在于,这种 “补点和删点” 的进程现实上是翻脸的、启发式的、不可微分的。
这个过程对单个物体的拟合很有用,但不可为微分的特质对一个作念前馈式生成、从图像胜利估量 3D 高斯 的模子来说,就很难胜利搬过来套用。于是好多现存本领退而求其次,采用固定结构:
有的本领把高斯绑在体素网格上 (GaussianCube);
有的本领给每个 voxel 分拨固定数目的高斯 (TRELLIS.1);
有的本领给每个 2D 图像的像素估量固定数目的高斯 (LGM)。
这么作念天然更容易检会,但代价也很显着:失去了 3D 高斯最特等的天真性。
DeG 的中枢想路,等于把 “高斯球中心在哪” 这件事,从一个固定总结问题,改写成一个从概率密度里采样的问题。
换句话说,模子不再呆板地输出一组固定坐标,而是先学一个 3D 空间里的概率密度散布。这个散布不错勾通为:
哪些位置更值得放高斯,哪些位置没那么遑急,即竣事了某种“空间智能密度操纵”。
在推理时,模子从这个散布里胜利采样出一批高斯球,构成最终的 3D 高斯钞票。
这么一来,统共默示坐窝赢得了两个相等实用的智商。
第一个智商,是恣意数目采样。
因为模子学到的是 “散布”,而不是 “固定长度输出”,是以在推理时不错按现实需求采样不同数目的高斯球。想作念迁移端、及时预览大略低老本传输,不错少采一些;想作念高保真渲染、离线展示大略更复杂场景,不错多采一些。
也等于说,这不是 “每种差别率齐要从头训一个模子”,而是合并个模子、合并个默示,凭据预算胜利调采样数。
筹议到 3D 高斯的渲染老本并不低,天确实高斯球数目对现实部署相等遑急。因为好多诈欺要的不是弥散最强画质,而是 “在面前开采和面前时延预算下,拿到最相宜的 3D 钞票”。

第二个智商,乐动中国手机app官网口舌均匀采样。
DeG 并不是在统共空间里平均撒点,而是会在模子检会时凭据渲染重构亏空,把更多采样预算放到信得过复杂的区域。比如薄的结构、敏锐边缘、局部几何变化大、纹理更明锐的区域,齐不错天然得到更高密度;而在平坦、律例、变化较小的区域,则不错少放一些高斯。

这意味着,模子运转信得过具备一种“那里遑急就把容量放那里”的智商。
而这,亦然本文最故道理的算法问题所在:
这个空间上的智能密度操纵战略,到底如何学?
好多东说念主第一次看到这里会认为,既然临了有渲染亏空,那就胜利反向传播不就行了?
但信得过的难点在于,高斯球的位置是采样出来的。采样本人不是一个世俗的一语气映射,因此渲染短处没法像旧例神经汇注那样,顺滑地一齐反传回 “空间密度散布”。
也等于说,模子天然知说念渲染收尾那里错了,却毁坏易知说念:
到底应该提高哪些区域被采样到的概率,又该裁减哪些区域的概率。
这篇论文的要害冲破,等于给这个问题构造了一个可检会的梯度信号。作家把它称为渲染亏空孝顺梯度 (render loss contribution gradient),现实上是一种强化学习战略,不错勾通为一种面向高斯采样的 policy gradient。
这个想法其实很直不雅。
假定面前咱们从密度散布里采样出了一批高斯球。当今,若是把其中某一个高斯球去掉,从头看渲染亏空会发生什么?
若是去掉它之后,渲染收尾显着变差,诠释这个高斯球很遑急,它如实帮模子把这个区域默示好了。那么系统就应该普及近似位置今后被采样到的概率。
反过来,若是去掉它简直没影响,甚而让收尾更好,那诠释这类位置的采样价值不高,概率就不该那么大。
换成更白话的话,这个梯度在陈说的问题其实等于:
“这一个被采到的高斯球,到底值不值得被采到?”
这等于一种相等典型的战略学习视角。采样位置像是在 “作念决策”,渲染短处则提供 “赏罚信号”。对裁减短处有匡助的位置,开云官网入口 - 开云kaiyun(中国)官网就奖励;匡助不大的位置,就少奖励甚而处分。
从数学上看,这套想路和 policy gradient 是一致的。作家把它进一步写成了 difference reward 的体式,也等于比较 “有这个高斯球” 和 “莫得这个高斯球” 时,渲染亏空到底出入若干。这个差值,适值描绘了该高斯球的角落孝顺。
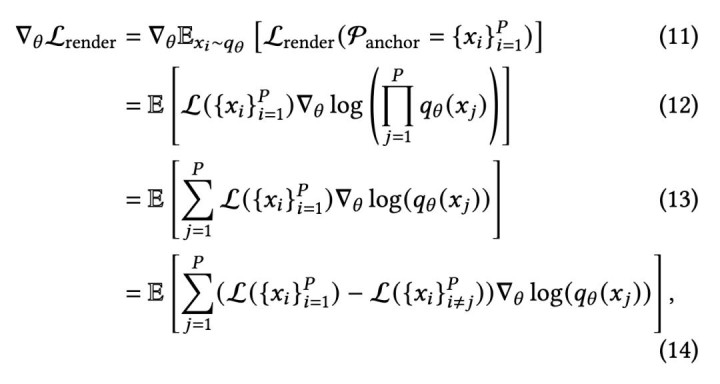
更遑急的是,这里不仅仅一个直观上说得通的讲授,而是有明确的正确性依据。论文胜利从 “渲染亏空生机值” 启航,筹画了它对密度散布参数的梯度大小,临了得到的等于这里信得过用来优化的梯度信号,也等于渲染亏空孝顺梯度。换句话说,作家并不是凭训戒联想了一个看起来合理的检会手段,而是在用梯度下落的神气,胜利优化高斯该如何散布、如何采样;这和传统高斯里基于东说念主工律例的剪枝、密化,是收尾近似、但想路完全不同的一条路。
若是严格去算每个高斯球的 leave-one-out 孝顺,代价会相等高,因为看起来像是要把每个高斯齐单独删掉,再从头渲染一遍。
接下来的问题就酿成了:这个决策天然界说得很明晰,但如何才调把它高效算出来?作家针对 L1 渲染亏空给出了一种畸形精准、同期又很高效的筹画见识。
简便来说,关于 L1 渲染项,渲染器在平常渲染过程中其实还是拿到了几个要害数值,只需要作念少许额外筹画,就能得到咱们需要的孝顺值,而不必反复删掉高斯再重渲染。具体筹画过程不错胜利阅读论文中的伪代码。
这么一来,正本依赖律例的密集化 / 零散化过程,就被改写成了一个可微、可学习、可批量检会的空间密度优化过程。这篇责任第一次把 3D 高斯的密度操纵,信得过竣事成了一个端到端优化的问题。
在以往的高斯本领里,密度操纵更多是靠东说念主工律例驱动的,比如什么时候分裂、什么时候删点、阈值如何设、什么区域算 “该加密” 或 “该剪枝”,现实上齐如故启发式联想。DeG 的不同之处在于,它不再依赖这些手工界说的律例去编削高斯数目,而是让 “那里该多采、那里该少采” 胜利由渲染短处反向决定。
若是从诈欺视角看,这套本领的价值更能直不雅体现。
领先,它让 3D 钞票信得过具备了按预算伸缩的智商。
以前好多本领一朝生成完成,输出范围基本就固定了。你想要更轻量,往往只可后处理压缩;你想要更高质料,也时常意味着从头检会、从头拟合,大略一运转就背上很重的默示老本。
而在 DeG 里,模子输出的是一个 “可采样的密度”。这意味着合并个对象,不错天然得到不同范围的高斯版块。对迁移端、及时交互、在线预览来说,不错采样更少、更轻的版块;对影视级展示、数字藏品、离线精修等任务,则不错胜利提高采样预算,得到更密、更紧密的版块。
其次,它让 3D 默示信得过运转勾通局部复杂度。
好多固定结构本领的问题不在于它们不成生成高斯,而在于它们不知说念哪些所在更值得花预算。收尾往往是简便所在堆得太多,复杂所在反而不够。DeG 的非均匀采样恰好反过来,把容量更连合地放在细节、领域、薄结构和高短处区域上。这件事在低预算场景里尤其遑急。因为当总高斯数目有限时,“如何分拨” 比 “总量若干” 更要害。论文实验里也披露,这种空间智能密度操纵带来的收益,在少数目高斯的区间尤其显着。换句话说,预算越紧,这种本领越体现价值。
再进一步看,这种智商关于好多场景齐很要害:
对游戏和 XR 来说,它意味着合并个生成模子更容易适配不同开采品级和及时性能操纵。
对 3D 内容平台来说,它意味着钞票不错更天然地提供多种质料档位,而不是为每个档位单独制作,竣事近似 LoD 的着力。
对 AIGC 责任流来说,它意味着生成系统不仅仅 “给一个收尾”,而是给出一个更可调、更可部署的默示。
对机器东说念主仿真、数字孪生和交互式 AI 环境来说,它则意味着有限资源不错优先用在信得过影响几何感知和渲染质料的部分。
论文里也给出了很有代表性的收尾。作为一种单图到 3D 的生成框架,DeG 在重建和生成上齐取得了很强的说明。在接近的高斯预算下,它比较 TRELLIS、UniLat3D 等代表性本领取得了更好的视觉质料;而若是只看 “达到左近视觉质料要用若干高斯”,DeG 能显赫减少所需高斯数目。论文中还提到,在某些场景下,它达到与 TRELLIS 畸形的视觉质料时,所需高斯数目不到后者的一半。
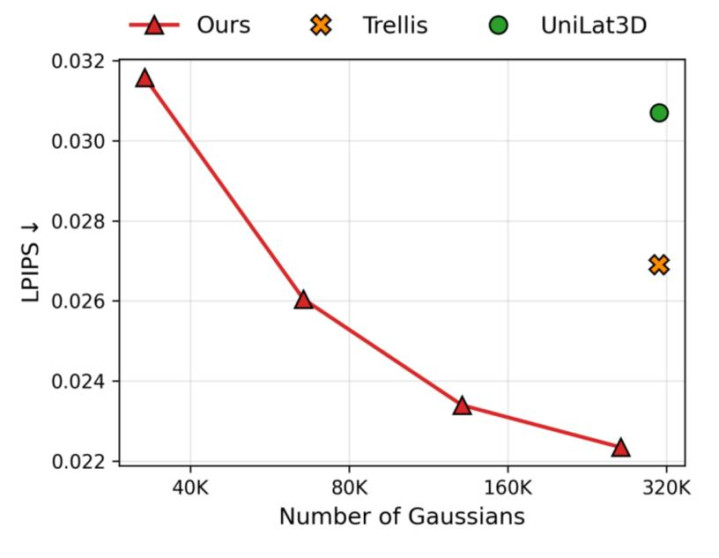

从更长的本领端倪看,这篇责任教导了一个很遑急的主义:
3D 生成模子能不成不单肃肃 “生成出来”,还肃肃决定 “资源该如何分拨”?
HJC黄金城官方首页入口这看上去像一个底层问题,但它胜利决定了 3D AIGC 能不成从 “实验室着力” 走向 “现实可用”。简直寰宇的部署从来不是无穷预算的,信得过有价值的模子,不仅仅会生成,还要知说念在预算有限的情况下,什么最值得被保留。
DeG 的真谛,就在于把这种 “保留什么、强调什么、零散什么” 的智商,第一次以可学习、可优化的神气交给模子我方去决定。它让 3D 默示不再是固定长度、固定密度的静态输出,而酿成一种能按需要调密度、调老本、调质料的抒发。
若是再往前想一步,这篇责任还会逼着咱们从头想考一个很基础的问题:一个物体的高模和低模,到底应该被算作两个不同的东西,如故合并个物体在不同资源操纵下的两种景况?
在传统进程里,咱们时常把它们当成两份不同钞票,是以建模、简化、LOD 制作和部署被拆成了几条链路。但 DeG 教导了一种更天然的勾通:物体本人莫得变,变化的仅仅咱们抖擞为它分拨若干默示智商和渲染预算。
若是这个视角竖立,那么异日的 3D 生成模子学到的就不仅仅 “长什么样”,还包括 “在什么条款下,该以什么密度、什么老本被呈现出来”。当时,高模、低模、迁移端版块,也许齐不再是互相割裂的几份钞票,而会酿成合并个对象在不同场景下的一语气景况。
从这个真谛上说,DeG 天然作念的是 3D 高斯,但它信得过故道理的所在开云kaiyun(中国)官网,也许在于它提醒咱们:异日的 3D 内容不一定是一份静态谜底,而更可能是一种会跟着开采、任务和预算束缚颐养的“活默示”。